
自前で用意した画像データの色味や光源環境の影響で学習や認識がうまく行かないことってありますよね ? そんなときに活躍するのがEqualizationすなわちヒストグラム平坦化です。
Equalization自体についてはたとえばこちらの記事(PIL でカラー画像を Equalize(ヒストグラム平坦化)する際の注意)にとても詳しく書かれていますので、ご参照下さい。
さて今回はこの記事にもある、コントラスト制限適応ヒストグラム平坦化 (CLAHE, Contrast Limited Adaptive Histogram Equalization) を使用したときの話しです。
いきさつ
OpenCV CLAHE の使い方はこんな感じになります。
clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8,8))
img_yuv[:,:,0] = clahe.apply(img_yuv[:,:,0])
ところがこのclipLimitの数値の意味がさっぱりわからない。 Wikipedia によると、ヒストグラムの分布においてclipLimitを超えた分を等分しすべてのbinに再配布するということだが、数値自体はノーマライズや変換の仕方に依存するので一概には言えないが、3~4の値を入れると良いらしい。
なんのこっちゃとなるわけですが、同じような疑問を持つ人はたくさんいらっしゃるようで、Stack overflowにこんなやりとり(What does clip limit mean exactly in OpenCV CLAHE?)があり、回答が比較的詳しかったので、翻訳してみました。
Question
ドキュメントによれば、clip limitはCDF (Cumulative Distribution Function) の傾きへの制限だと言っています。しかしOpenCVでは、このパラメータは0~999まで設定できます… この最大値の意味もよくわかりませんが、PDF (Probability Density Function) の総計は1ではないのでしょうか ? どうやって傾きを1よりも大きくできるのでしょうか ? 別の言い方をすると、clip limitはすべてのグレイレベルの合計への制限です。であればたとえば、tileを(8, 8)に設定すると、どのtile内のグレイレベルの合計も64を超えないはずです。しかし、実際にclip limitに64以上の値を設定しても、結果は変化し続けます。これはどういうことなのか、教えて下さい。
Answer
clip limitは次のように実装されています:
- まずすべてのピクセルに対して輝度の確率密度関数 (PDF) が計算されます。たとえば8bit階調の画像だと、PDFは0から255の輝度値に対する配列になります。PDFは画像の中で当該輝度値を持つピクセル数によって計算されます。たとえば PDF(輝度=0)=26 は、画像内で輝度0のピクセルが26個であることを意味します。
- 一度PDFが計算されると、PDFのすべての要素が探索され、clipLimitを超える要素がないか判定されます。たとえばclipLimitが4だとして、PDF(0)=26から始めると26は4を超えていますから、clipped=clipped+pdf[i]-clipLimitという式によって輝度0のピクセル数が4に制限されます。ここでclippedは0から始まります。すると、clipped=0+26-4=22になります。この処理がPDF(輝度=1), PDF(輝度=2), … , PDF(輝度=255)に対して行われます。最終的にclipLimitを超えるPDFは無くなり、クリップされたピクセル数は変数clippedに保存されます。
- そして、クリップされたピクセル数はPDF配列に均等に再分配されます。たとえばclipped=128とすれば、ざっくりPDFの要素ひとつおきにピクセル数が1足されます。仮にPDF(0)=4, PDF(1)=2, PDF(2)=0とすれば、クリップ分の再分配後はPDF(0)=4+1, PDF(1)=2, PDF(2)=0+1のようになります。つまり、PDFがclipLimitに制限された輝度においては、再分配があれば最終的にclipLimitよりも若干大きくなることになります。
Wikipedia によると、clipLimitは通常3から4に設定されるのだそうです。clip limitが上記のように実装されている場合、ヒストグラムのどの要素も最大値が制限されますから、ヒストグラムの隣接する二要素間の最大の傾き(すなわち輝度の変化)も制限されます。
- 現実的ではないけれどもわかりやすい例で言うと、1920 x 1080 ピクセルの画像においてすべてのピクセルの輝度が1とします。つまり当初のPDFは、PDF(1)=2073600でそれ以外のPDFはすべて0になります。このとき、累積分布関数 (CDF) の傾きは、(2073600-0)/(1-0)=2073600になります。
- ここでこの画像全体のヒストグラムに対してclipLimit=4を適用することを考えます。するとクリップ後のPDFは、PDF(0)=0, PDF(1)=4, PDF(2)=0, … のようになります。クリップ後の傾きの最大値は(4-0)/(1-0)=4になりますから、2073600に対してとても小さな値になります。そしてクリップ分の再配布後は、ざっくりどのヒストグラムのビンも8100ピクセル足されますから、PDFはPDF(0)=8100, PDF(1)=8104, PDF(2)=8100, … のようになります。このとき、CDFの傾きの最大値は、(8104-8100)/(1-0)=4となります。
あなたの質問にあるとおり、PDFの総計は1です。しかしながら、PDF配列としてここではピクセル数が使われています。これは本来のPDFの分子の部分に相当します。画像サイズを1920 x 1080とすると、実際のPDFは:
- Probability(intensity = 0) = 4/(1920×1080) = 4/2073600
- P(intensity = 1) = 2/2073600
- P(intensity = 2) = 0/2073600
のようになりますから、これらの分数の合計は1になります。しかしOpenCVのような確率密度関数の実装だと、PDFは:
- PDF(0) = 4
- PDF(1) = 2
- PDF(2) = 0
となるので、分母がないので合計は1にはなりません。
実装については OpenCV source code を参照してください。尚、クリップ分の再配布に関して、わかりやすさのために概略的に説明しています。
さいごに
とてもわかりやすい説明でしたが、結局はWikipediaにあるこの図のとおりですね。
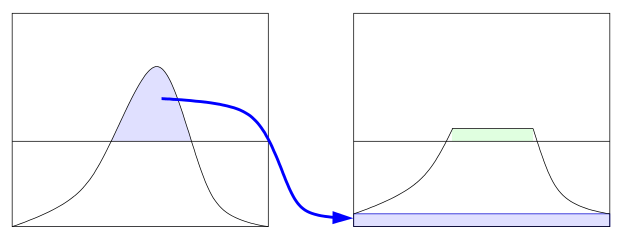
ただしOpenCVではclipLimitの値はピクセル数で扱われているというのがポイントでしょうか。一応スッキリということで。