
numpy.reshapeは気をつけて使おう ! の続きです。この記事の最後でも触れましたが、torch.viewも同様なわけですと言ってるそばから間違っていたという話しです。しかも学習という意味でデータ構成が大きく間違っているわけではない場合症状が微妙なので間違いに気づきにくいということもあり、思うところも添えて行きたいと思います。
今回もPyTorchは悪くないのですがPyTorch上でハマったということで…
気づいたきっかけ
前回の記事のとおり、Kerasで動作していたLSTMの瞬き検出器はPyTorchでも動作するようになりました。そのLSTMをベースにマルチタイムスケールのLSTMをおためし実装していたときのこと。マルチタイムスケールはその名の通り、シーケンス長の違う複数のLSTMを並列に動かしてコンカチしてFCL (Fully Connected Layer) に入れるものです。
そう、シーケンス長が違うデータを用意する必要がある複雑なケースだったため、あらたな実装をしていて気づいたわけです。
間違っていたポイント
kernel_initializerって学習の収束に大事かも に掲載したLSTMのプログラムに間違いがありました。class LSTMのforwardメソッド内の以下の部分です。
修正前:lstm_out, _ = self.lstm(ncf_sq.view(batch_size, sq_len, feature_size))
修正後:lstm_out, _ = self.lstm(ncf_sq.permute(0, 2, 1))
なんでtorch.transposeではなくtorch.permuteなのかについては PyTorchのtransposeはnumpyのtransposeと若干違う(PyTorchで軸の順番を入れ替える方法について を参照ください。 あわせて【PyTorch】Tensorを操作する関数(transpose、view、reshape)も読んでおくと勉強になります。
思うところ
今回間違いに気づくのが遅れたのは、学習は収束しInferenceもそこそこ正しく動作した、というのがあげられます。
そもそもnumpy.reshapeやtorch.viewを使うことによってどういう状況になっていたかということを考えると、n x mの元画像に対して、転置でm x nの画像を作りたかったところが、元画像のデータの順序が変わらずにm x nの画像になっていたというわけです。
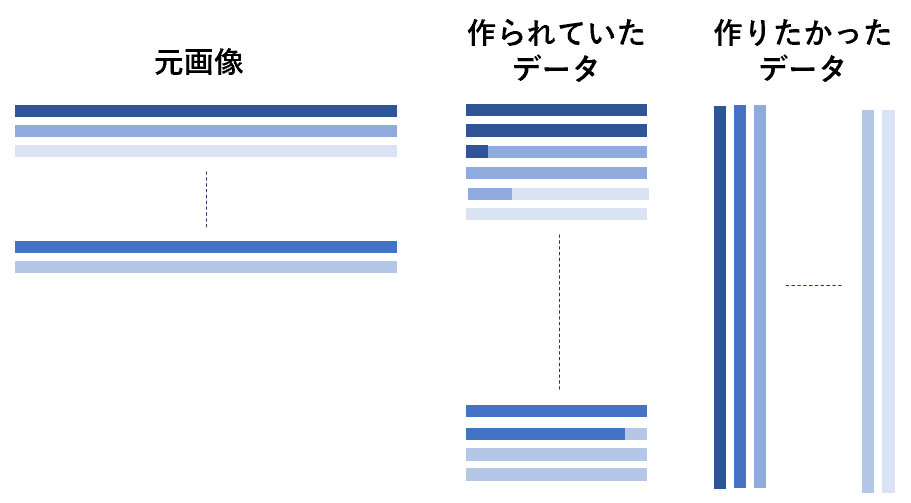
極端に書くとこんな感じですね。これにコンボリューションかけたりすると、明らかに違った結果になっていくはずですが、実際には画像の縦横比がそれほど違わなかったり、画像の性質があまり変化しなかったりすると、それなりにInferenceできてしまって間違いに気づきにくいというのは結構ありそうです。
データのAugmentationの一種としてこういうのもあり得そうですし、それくらいわかりにくくなってしまう場合があるので気をつけないといけないということですね。
さいごに
たぶんもう間違いはないと信じていますが、こういったケアレスミスは気づかないとそのまま世の中に出回ってしまったりするので慎重に慎重を重ねたいところです。
他人のサンプル実装をコピペで動かしたりすることもあると思いますが、そのサンプル実装ではnumpy.reshapeやtorch.viewで問題なかったものでも、自分のケースでは間違っていることはままありますので、コピペにも注意は必要ですね。
とにもかくにも気づいてよかった。また少しスッキリしました。