
VR・ARを直接的にささえる技術には、機構系や光学系デバイス、トラッキング、グラフィックスなどがあることはすでにこれまでのレクチャーで勉強しました。
今回はもう少し間接的にささえる技術、あるいはコンテンツ制作に重要な技術について触れて行きます。具体的には、360度動画、セグメンテーション、ライトフィールド、レイトレーシングの4つを取り上げ深掘りして行きます。
360度動画
360度カメラ

360度動画を制作するのになくてはならないのが360度カメラです。やはり有名なのはRICOH THETAですね。これはZ1ですが、前面と背面に魚眼レンズが1基ずつあって、二つの半球を貼り付けて球の映像を作ります。標準的なものだと全天球30fpsで4K解像度、アクションカムのInsta 360 One Rだと全天球30fpsで5.3K解像度です。(360度動画で言う解像度というのは見えていない部分も含めた全天球のデータ解像度ですので注意して下さい)

さらに解像度を上げようとすると、例えばこちらはアクションカムのGoProを6台使ったGoPro Omniですが、6台で8K解像度を達成しています。
ここで、360度VRで言う解像度について触れておきます。たとえば4Kテレビでは4K映像をフルに見ることができますが、「4Kの360度映像」の場合全天球全体で4Kデータということになるので、実際にVRヘッドセット上で見えている映像は多くの場合4Kの2分の1以下ということになります。このあたりは、こちらの記事(「VRゴーグルと解像度の関係」)の説明がわかりやすいです。

360度動画は全天球ですが、モノラルカメラで撮影したものがベースの場合が多く、VRヘッドセットで楽しむ場合には3D立体視になっていない(両目に同じものを提示する場合すべてのオブジェクトは無限遠になります)ケースも多く見かけます。
これに対してGoogleが策定した半天球の規格 VR180フォーマット があります。ステレオカメラでの撮影が前提なので、半天球ではありますが3D立体視が可能な規格になっています。
VR180が立ち上がったことから、VR180はステレオカメラで、全天球360度は単眼モノラルで撮影するVuze XRのようなカメラもありますし、ハイエンドのミラーレス一眼を2台組み合わせて高品質な180度のステレオ映像を撮影するものなどもあります。
スティッチング
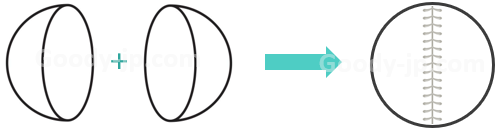
さて、360度動画を作る上で避けて通れないのが画像を繋ぎ合わせることです。これをスティッチングと言います。たとえばRICOH THETA Z1で撮影した場合、前後二つの半球映像が撮影されますが、これを繋ぎ合わせたものが全天球画像になります。
この動画は、半球画像がスティッチされて360度動画になるようすがわかりやすく示されています。前後のカメラのそれぞれが180度より広角になっていて、スティッチングのためのオーバーラップ領域が確保されているために、比較的スムーズなスティッチングが可能になっています。
スティッチングは各カメラベンダーがスティッチャーと呼ばれるアプリケーションやプラグインでサポートしていて、各社各様のアルゴリズムとなっています。実際3種類のカメラのスティッチングラインの比較動画を見ると、明らかな違いがわかりますね。
モノラルの360度動画として見る分にはこのあたりは致命的とまでは行きませんが、VR機器でステレオ動画として見る場合には、スティッチングのクオリティはとても重要になります。ステレオ矛盾に対して視覚はとても敏感です。一見左右でほとんど違いがなく、スティッチングラインも見えないような状態でも、若干の差異が目への違和感となって現れます。またその状態で長時間見続けていると、激しい目の疲労や不快感につながることがあるので、注意が必要です。
グーグルのアプローチ
ここで、Googleの360度動画へのアプローチに着目します。毎年のようにグレードアップしてくるような印象ですが、最初に出てきたのがGoogle Jumpでした。
Google Jump / GoPro Odyssey
Google Jumpは多数のアクションカムを並べて撮影した動画を360度ステレオ動画に編集するプラットフォームで、その中核は撮影された多数の動画をスティッチングし、左右の目から見たシーンを再構成して高品質なステレオ画像を生成する、クラウドシステムです。そしてこの動画にもあるとおり、最初のJump ReadyなカメラシステムがGoPro Odysseyです。
GoPro Odysseyは16台のGoProを横に円形に並べたもので、これで撮影した16本の動画をGoogle Jumpに入力すると、スティッチングされハイクオリティな3D360度動画が出力されるというわけです。こちらの記事は、円形に並べたモノラルカメラアレーの画像から、左右の目から見たシーンをソフトウェア的に再構成するあたりについて、詳しく触れられています。
実際博物館映像などありますが、かなり綺麗なものです。このような構造ですから、動画ではありますがあまりアクティブな撮影には向かないですね。
Google Light Field
次はGoogleのLight Field再構成のアプローチの一つ目で、縦に弓状に16台のGoProを並べたものを回転させて撮影します。静止画用途になりますが、ハイクオリティな3D360度静止画の撮影を実現しています。6DoFということで、回転方向だけでなく(ある程度の範囲の)前後左右の視点の動きに対しても、ソフトウェア的にシーンを再構成できるもののようです。
動画の中でインタビュアーが、撮影したものをどこにあげるんだい、YouTubeの360度動画は3DoFだよね、みたいな質問をしていますが、先ほどの博物館映像のような用途には向いていると考えられます。
そしてGoogleのLight Fields再構成のアプローチの二つ目は、昨年のSIGGRAPHで発表されたもので、46台のGoProを直径1m弱の球面上に配置して撮影するライトフィールドカメラシステムです。
要は、最初はカメラを水平方向に並べ、次に垂直方向に並べ、そして今回は立体的に並べたということですね。ここまでくるとスティッチングというよりはAIによる画像のレイヤー化と結合という感じになってくるのですが、クオリティの高い360度動画の撮影にGoogleがとても力を入れていることが伺えます。
画像処理
昨今のコンピュータビジョンの発展は凄まじいものがありますが、大きく画像認識系と画像生成系の二つのカテゴリーに分けられます。
画像認識
画像認識系は深層学習DNNを使用するものが主流で、VGGやMobilenetと言った汎用的に使えるネットワークですでに学習済みのものがいくつもあります。Keras Documentation を参照すると、ImageNetで学習した重みをもつ画像分類のモデルとしてこれらのモデルが利用可能です。
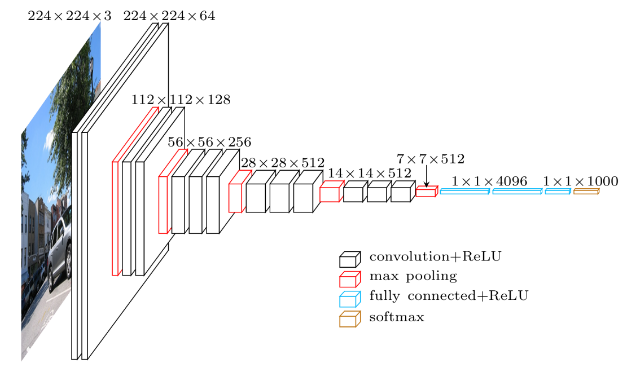
たとえばVGG16はこのようなネットワーク構造をしていて、CNN (Convolutional Neural Network) と言いますが、元画像が与えられると、様々なサイズのフィルターによって畳み込まれて、最終的に特徴量が出力されるというものです。その特徴量を使って画像を分類します。
GoogleのTensorflowとかFacebookのPytorchとか、誰でも自由に使えるプラットフォームが主にPythonベースで用意されていて、上記のように代表的なネットワークは学習済みのものが用意されています。もちろん自分で全てのネットワークを組むこともできますが、こういった学習済みのネットワークに分類器を自分で追加して、転移学習あるいは追加学習を行うことでも十分正確な認識器が得られることが多いです。
その場合、開発者は識別したい大量の入力画像とラベル(答え)を用意して、ちょこっと分類器を付け加えて、あとは数時間かけてネットワークを学習させるだけで、車、飛行機と言ったオブジェクトや数字・文字の認識を行うことができます。つまり結構簡単に認識器は作れます。今や様々な認識器が作られて、しかもソースコードもGithubなどで共有されているのですぐに試せる、大変便利な世の中になっています。ここでは二つほどご紹介します。
まずYOLOですが、バージョンが更新されて性能も改善され続けています。ここでは詳しくは説明しませんが、興味がありましたら論文 (You Only Look Once: Unified, Real-Time Object Detection) にも目を通して見てください。このあたりの記事も参考になるでしょう。またソースコードもありますので、簡単に試すことができます。
もうひとつはOpenPoseです。こちらも性能が改善されたバージョンがリリースされていますね。発表された当初世界中を驚かせた技術です。こちらも詳しくは説明しませんが、興味がありましたら論文 (OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields) にも目を通して見てください。こちらもソースコードが開示されていますので、簡単に試すことができます。
画像生成
一方画像生成系は、Auto-encoderという技術がベースにあり、最近ではGANという技術が大きく発展しています。もはや写真とCGの区別がつきにくくなってきているレベルの技術も多数あり、画像認識系の教師データの水増しにも使われるようになってきています。
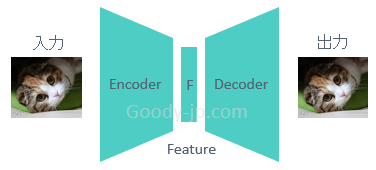
そのベースとなるのがオートエンコーダーで、認識器ネットワーク (Encoder部分) で特徴量にしたあとに、その特徴量からGeneratorネットワーク (Decoder部分) で画像を生成し、入力画像と同じになるように学習させるものです。Featureを絞りすぎると入力画像の再現が難しくなりますし、ノイズ等を注入することによって似て非なる画像を生成できます。このあたりはこちらの記事「オートエンコーダ(自己符号化器とは)」が大変参考になるでしょう。
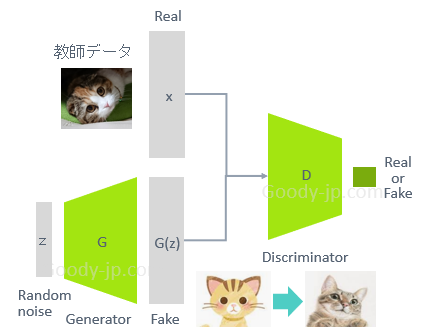
これを応用したものに、GAN (Generative Adversarial(敵対)Network) があります。これはReal画像とGeneratorで生成されたFake画像を比較して、Discriminator(弁別器)にどちらが本物かを当てさせて、答えを教えてDiscriminatorを学習させつつ、GeneratorにはDiscriminatorをだませるほどクオリティの高いFake画像を生成させるように学習していくというものです。これによって、最初はなんとなく猫っぽいCGをを生成していたGeneratorが、学習を続けて行くことによって、実写と見分けがつかない猫画像を生成するようになる、というわけです。
こちらの記事「GAN(敵対的生成ネットワーク)とは|意味・仕組み・応用例」にもあげられていますが、CycleGANとStyleGANは当初世界中を驚かせた技術と言っても過言ではありません。是非以下の動画を見て概要を知っておきましょう。
セグメンテーション

次に紹介するのは、AIいわゆるニューラルネットワークの応用例の一つと言えますが、Semantic Segmentationです。Semanticは意味論という意味で、ただ単にセグメンテーションするだけでなく、カテゴライズするということです。この絵のように、人、車、道路、歩道、看板、建物、木、空などを認識して、ピクセルレベルで区分けします。
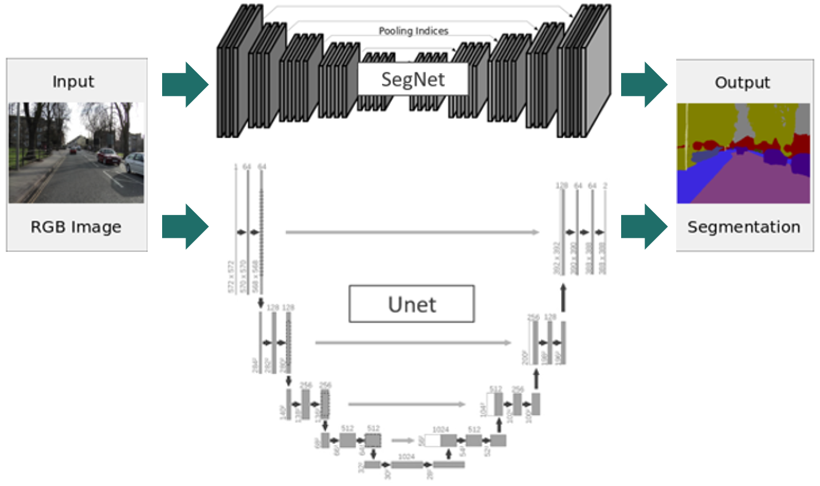
セグメンテーションのためのネットワーク例としては、SegNetやUnetがあげられます。基本的には画像生成系であるオートエンコーダーと類似の構造を持ちますが、入力はセグメンテーションしたい画像であるのに対して、出力はセグメンテーションマップ(ピクセルレベルでラベル付けしたもの)となります。画像とセグメンテーションマップの大量のペアを使用して学習することにより、セマンティックにセグメンテーションすることを実現します。
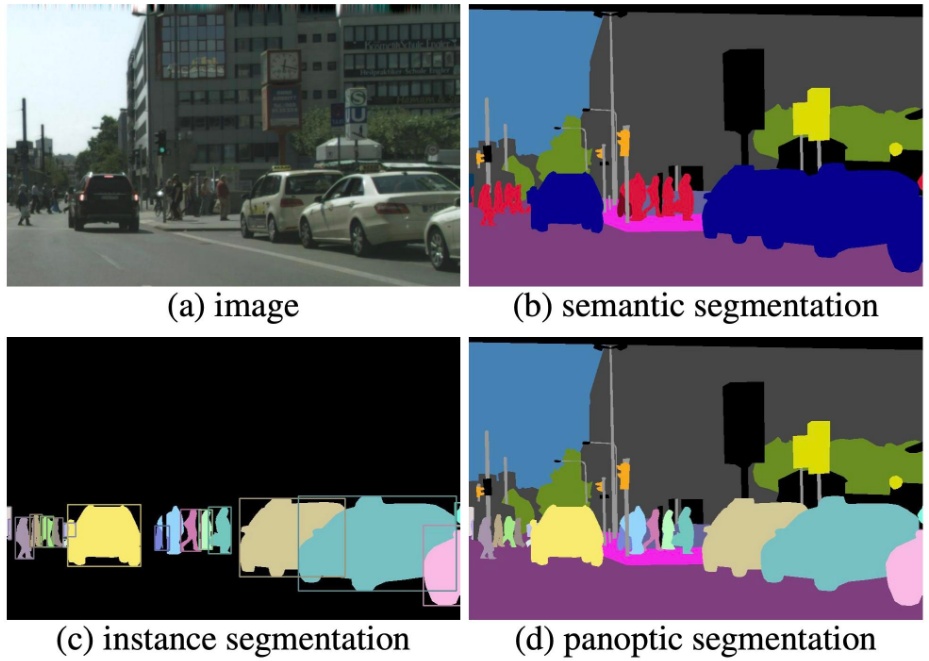
セグメンテーションの意味論も、ただ単にカテゴリーで分別するもの (Semantic Segmentation) から、人や車など数えられるオブジェクトを個体単位で識別するもの (Instance Segmentation) や、それらを融合させた Panoptic Segmentation へと発展を遂げています。
ここでは代表例として、FacebookのDetectron2の動画を見てみましょう。セグメンテーションだけでなく、人間の身体のパーツ認識やポーズトラッキングもできるもので、しかもソースコードも公開され誰でも試すことができますから、興味があったら触ってみることをおすすめします。
ではこのセグメンテーション技術を何に使えるかと言うと、特にAR向けには有用です。
街中の空間理解では、道路、人、車、街路樹、建物などを検出することによって、ナビゲーション情報の重畳に効果的です。以前も紹介したAR Cityのようなユースケースですね。もちろん地磁気センサー情報や加速度センサー情報をベースにスマートフォンの姿勢を推定しカメラの向きの推定もしますが、それに加えて地面や道路の認識や建物の認識はテキスト情報やARオブジェクトを貼り付けるのに大変重要です。
また、何気ないシーンでも地面と人やオブジェクトを理解できれば、オクルージョンを考慮したキャラクターの描画が可能になります。こちらも以前も紹介したPokemon GOのようなユースケースですが、ナレーションでも “using neural network”と言ってますね。
そして、部屋の空間理解では、フロアー、テーブル、ソファー、ベッドなどが検出できればその上は平面的なので、CGオブジェクトを正しく配置することに使えます。ARCoreでも昨年からDepth APIがサポートされ、Depth検出による空間理解をサポートしているので、動画を見てみましょう。
あれ ? セグメンテーションの説明はないけど ? と思われたかも知れません。実際ベースにある技術は、モノラルカメラを動かすことによるDepth認識ですね。VR・AR機器のトラッキング その3でやったSLAM技術がベースになります。どこまで輝度や特徴点を使っているかはわかりませんが、要は単眼カメラを動かすことによって生まれる視差から深度情報を得ます。
動画のEnhanced Depthのところで”Depth from Motion is fused with the state-of-the-art Machine Learning”とありますが、このMachine Learningの部分でフロアー認識や平面認識などを利用して深度情報の最適化が行われ、よりくっきりしたDepth Mapが生成されます。
ライトフィールド
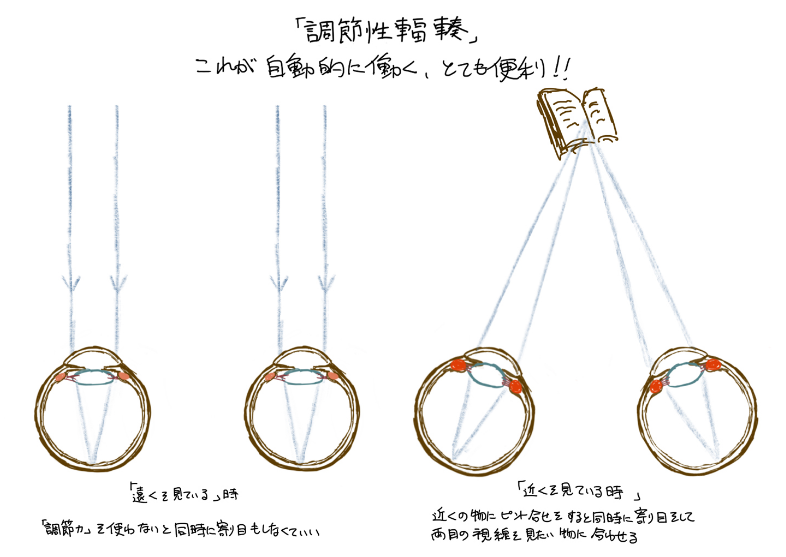
ライトフィールドという言葉は非常に広義ですが、総じて視覚が光学的に正しい状態を再現できることを指します。ここではユーザーが見ている視点の距離感に応じた正しい視覚提示を行うためのアプローチについて考えて行きます。視覚的な距離認識としては、輻輳すなわち視差による深度認識と、レンズ(水晶体)厚み調節による視点への焦点調節がありますが、特に後者すなわちレンズ厚み調節と直接関連するトピックになります。輻輳とレンズ厚み調節の関係については、『調節機能』ピントあわせの機能についてをご参照下さい。また以下の図では輻輳だけでなく水晶体の厚みも異なって書かれていますので、着目してください。
VRの焦点距離問題
VRの焦点距離問題は、画面のステレオ表現により輻輳はオブジェクトの距離感と合いますが、そのオブジェクトはディスプレイ上に描画されるので、レンズ(水晶体)の厚みとしての距離感はディスプレイに固定になってしまうという問題です。
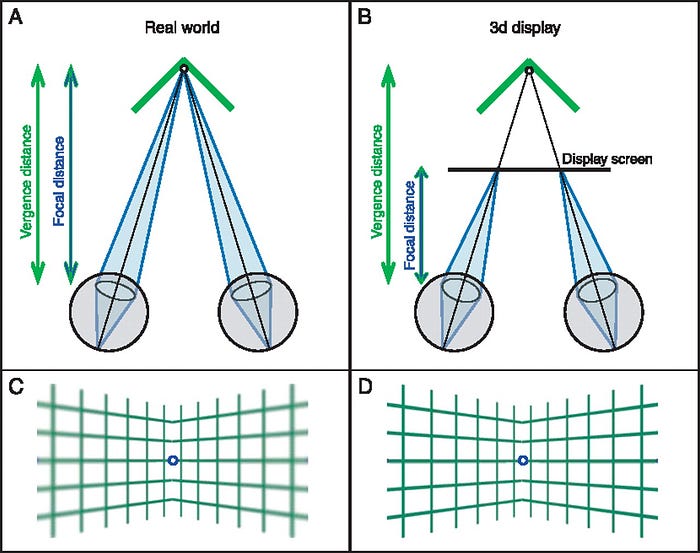
上の図を見てみましょう。左のように現実世界である1点を見ているとき、その点の方向に両目が内向き(その角度を輻輳角と言います)、レンズの厚みはその点の距離に合わせられます。結果手前にあるものはぼやけることになります。
一方VRの場合には、3D立体視のためにオブジェクトが左右で内側にずれた画面がディスプレイに表示されます。この結果、輻輳角は現実世界と同じ状態になります。一方レンズ厚みはオブジェクトの距離に合うわけですが、そのオブジェクトはディスプレイ上に表示されているため、右のようにディスプレイの距離に合うことになります。また、輻輳的にはバーチャル空間内のさまざまな距離のものを見ることができますが、すべてはディスプレイ上に描画されているものなので、レンズ厚み的にはすべてのものが一定の距離にあることになり、結果立体視領域全体がくっきりした画になります。
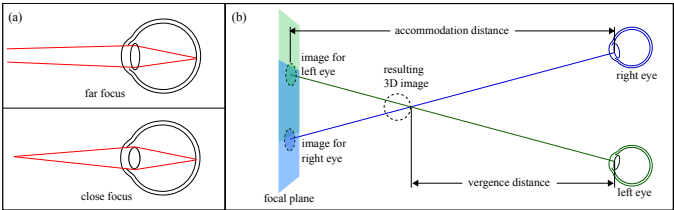
もう少しブレイクダウンしてみましょう。VR・AR機器の構造 その1 でやった通り、一般的なVRヘッドセットで虚像ができる距離はおよそ1~2mに設定されています。虚像よりも遠くにあるオブジェクトに関しては最初の図のようになり、全体がくっきり見えます。一方虚像よりも近くにあるオブジェクトを見る場合には、上の図のようにディスプレイよりも手前で像を結ぶことになります。つまり、水晶体のレンズフォーカスはディスプレイに合っているのに対して、3D立体像はディスプレイよりも手前に像を結びますから、結果ぼやけて見えることになります。そうなのです、虚像よりも手前にあるオブジェクトは全てぼやけてしまうのです。これがVRの焦点距離問題の中でも深刻な部分です。
Oculusのアプローチ
この問題を解決できる手法はいくつかありますが、ここではOculusのアプローチを二つ紹介します。視線推定やディスプレイ周りあるいはレンズ周りへの追加の機構は必要になりますが、Varifocal(可変焦点距離)という技術があります。VR・AR機器の構造 その1 でやりましたが、VRヘッドセットのレンズとディスプレイ間の距離を変えると焦点面すなわちディスプレイの虚像の距離が変わります。この手法はそれを応用します。
一つ目のアプローチは、ユーザーの視点の距離に応じてディスプレイの距離をメカ的に変えるというものです。一般にレンズとディスプレイの距離を1cm程度短くしただけで虚像の距離は半分程度に縮まるので、短い距離調整で大きな効果を得られます。式で言うと、1/f = 1/a – 1/bでfは不変でaを変えることによってbを変えるわけですね。このあたりについて問題提起から解決手法までとても詳細に説明されている動画がありますので、少し長いですが是非隅から隅まで見てみましょう。
この動画はDome1の世代のものなので試作感たっぷりのメカ構造で動作時の音もかなり気になるものですが、Dome2ではかなり洗練されたものになっています。とは言えディスプレイをメカニカルに動かすのは大変ですよね。なので、メカ的にディスプレイを動かす代わりに、焦点距離を変えられるレンズを利用して同様の効果を得ようというのが二つ目のアプローチです。この場合を式で言うと、aが不変でfを変えることによってbを変えるわけです。Michael AbrushさんのDome3講演動画がありますので、見てみましょう。
レンズ側で焦点距離を変えられることになって、随分と現実的な構造にはなりましたね。ただし、どちらの手法を取るにせよ、ディスプレイが1枚しかない前提では虚像面も1枚(1か所)になるので、虚像面よりも遠くにあるオブジェクトのボケを再現するためには焦点距離に応じたボケをレンダリング(描画)する必要はあります。
一つ目の動画の冒頭部分に3枚1組のディスプレイの話しが出て来ます。レンズからの距離が異なる3枚のディスプレイによって、3枚の虚像面を構成することができるので、これをユーザーの視点に応じて切り替えることにより、近中遠3段階の焦点距離への対応が可能になります。
実際 VR・AR機器の構造 その4 でやりましたが、Magic Leap Oneには片目ごとに2枚のウェイブガイドコンバイナーがあります。現状はこれをユーザーの視点に応じて切り替えることによりbifocalを実現しています。理論的には複数枚のディスプレイを同時に利用することによって、任意の焦点距離に対応できる可能性がありますが、現時点ではまだ技術的に難しいようです。
ARの焦点距離問題

一方ARにも焦点距離問題があります。ここではOptical See-throughのARゴーグルを仮定しますが、ARゴーグルを装着している人がSee-throughで見ている風景は現実世界なので、見ている物体の距離に応じて水晶体の焦点距離が変わります。Magic Leap Oneのときに触れたのですが、遠くを見ているときは近くがぼやけて、近くを見ているときは遠くがぼやけます。
それに対して、ARでCGオブジェクトを重畳する場合にも、本来はそれを踏襲しなければなりません。すなわち、この絵のように奥行方向に複数のミツバチを重畳する場合に、ユーザーが近くを見ているのであれば近くのミツバチのみはっきり描き、遠くのミツバチはぼやかす必要があります。
VRに比べるとあまり深刻な問題ではありませんが、ARにも同様の焦点距離問題は存在することは知っておきましょう。そしてライトフィールドとしてはもっと深刻な問題がARには存在します。その話しに移りましょう。
ARの二つの問題
引き続きOptical See-throughのARゴーグルを仮定しますが、深刻な問題が二つ存在します。一つは重畳される映像が半透明になる点、そしてもう一つはきちんとした影を作れない点になります。
半透明の問題

そもそもOptical See-throughなのだから仕方がないとも言えますが、何も対策をしなければ左の画像のようにARオブジェクトは透き通って見えてしまいます。これを右の画像のようにくっきりとした表現に近づけるアプローチがいくつかあります。ここでは論文 “Itoh, Y., Hamasaki, T., & Sugimoto, M. (2017). Occlusion leak compensation for optical see-through displays using a single-layer transmissive spatial light modulator. IEEE transactions on visualization and computer graphics, 23(11), 2463-2473.” を引用させて頂き少し掘り下げて説明したいと思います。
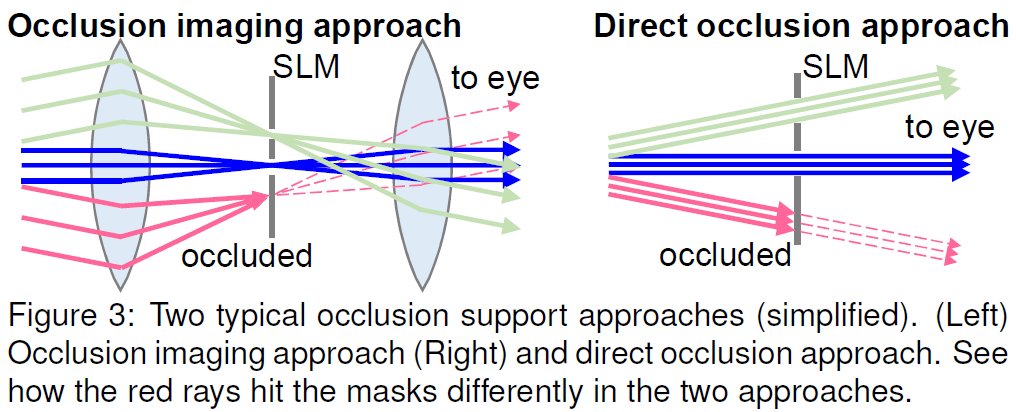
基本的に重畳画像をくっきりさせるためには、ピクセルレベルでマスクを作って現実世界が見えないように遮断する必要があります。この技術のことをPixelated Occlusionと言います。主に二つのアプローチがあり、一つは左の図のようなOcclusion Imaging、もう一つは右の図のようなDirect Occlusionです。
Occlusion Imagingでは、実世界の光は左側レンズを通して透明のSpatial Light Modulator (Polarizers + LCD) 上に結像します。左側のレンズによって屈折された光路を元に戻して正しい実世界のパススルーを復元するために右側のレンズが必要になります。SLMでマスクを生成しその上に重畳画像を描画することにより、重畳画像はシャープでピクセル精度を持ちますが、レンズ(水晶体)の焦点距離はSLMに制限されます。
一方Direct Occlusionでは、実世界の光はSLM面で結像されず、直接目にパススルーされます。ユーザーの視点に応じてレンズ厚みは調節されますので、重畳されるARオブジェクトが置かれる場所に応じたボケ表現がなされることが望ましい状態になります。
SLMは VR・AR機器の構造 その3 でやった透過型液晶ディスプレイ (LCD) だと思って下さい。LCDはピクセル毎に光をどれくらい透過するか制御できるパネルでした。これを使ってマスクするというわけです。
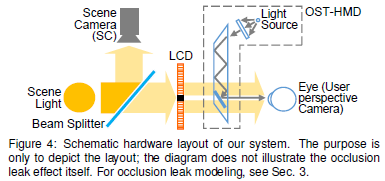
提案手法はこの図のようなシステムになります。ARオブジェクトやマスクを生成するためには実世界の映像が必要ですから、Scene Cameraで撮影します。この環境映像をもとにARオブジェクトやマスク用のデータを作成し、マスクはLCD上に生成、ARオブジェクトはコンバイナー上に表示することにより、くっきりとした重畳画像を生成することができるというわけです。動画がありますので見てみましょう。
影の問題

もう一つはきちんとした影を作れない問題です。正確には作れないわけではありませんが、きちんとした影をつくるためには環境の光源を正確に把握し、さらに重畳するオブジェクトのフロアーからの位置を正確に把握し影を再現する必要があるため、とても難しいということですね。これに輪をかけて重畳画像の半透明問題があるため、現状影を正確に作れたとしてもとても見えにくいという結果になってしまいます。
この問題に対しても、Pixelated Occlusionが有効であることは明らかですが、さらに光源位置とARオブジェクトの浮き具合に応じた影の生成という部分については、残念ながら決め手に欠いているというのが実情です。
半透明や影以外にも、ARならではの問題として、特に重畳されたオブジェクトを手でつかむ場合、正確には指に隠れている部分と外に出ていて見えている部分を正確に表現するべきですが、現状の汎用技術ではそこまで対応するのは難しく、手の甲の上に画像が重畳されてしまうのが現状です。
この問題に対しては、GrabARというAIベースの技術が提案されています。動画もありますので、興味がある方は見てみてください。オクルージョンを正確に表現することの重要性を感じるとともに、依然として何か空を掴んでいるような違和感がありますね。やはりここでも影の表現の重要性というのは感じざるを得ません。
レイトレーシング
そして最後にご紹介するのがレイトレーシングです。こちらはRTX3080でレイトレON/OFFを比較した動画です。ぼんやり見ているだけだとレイトレOFFでも結構きれいだと思ってしまうかも知れませんが、この動画のコメント欄にも目を向けると、さらに勉強になります。
コメントにもありますが、たしかにリアルタイムレイトレーシングが流行ってきてから、夜の水たまりの表現がやけに増えた気がします。レイトレの効果がわかりやすいシーンの代表ですね。
そんなこんなで、コンピューターの演算能力の向上とともに特に最近盛り上がっているレイトレーシングですが、その歴史は高々50年という新しいものです。
レイトレーシングの歴史
レイトレーシングの歴史に簡単に触れておきましょう。
- 1969年に IBM の Arthur Appel が “Some Techniques for Shading Machine Renderings of Solids” で最初に説明した技法で、2D 画面の各ピクセルからシーンの 3D モデルへと光線の経路が追跡されるもの。レイトレーシングの原点と言われる。
- 1979年の論文 “An Improved Illumination Model for Shaded Display” で、現在のNVIDIA Researchに所属している Turner Whitted が、反射、陰影、屈折を捉える方法を示した。またこの時期レイトレーシングの映画への適用が飛躍的に進んだ。Whitted の技法では、光線がシーン内の物体に当たったときに、その影響を受ける物体の表面にある点の色と照明の情報によってピクセルの色と照度が変化し、また光線が光源に達する前に異なる物体の表面で反射するか通過した場合、これらの物体すべての色と照明の情報が、最終的なピクセルの色に影響を及ぼすもの。
- 1984年に Lucasfilm のRobert Cook, Thomas Porter, Loren Carpenter は “Distributed Ray Tracking” に、それまでカメラのみで撮影できた多数の一般的な映画制作技法(モーションブラー、被写界深度、半影、透光性、不明瞭な反射)をレイトレーシングに組み込む方法を詳述した。
- その2年後に CalTech の Jim Kajiya 教授の論文 “The Rendering Equation” によって、シーン全体における光の散乱の表現を改善するため、コンピューター グラフィックスの生成方法と物理学を対応付けた。
ということで、理論的には1980年代に確立した手法が、ハードウェアの進化によりようやくリアルタイムに処理できるかどうかというレベルに昨今達しようとしているわけです。
ラスタライズとレイトレーシング
レイトレーシングが盛り上がりを見せている昨今ではありますが、現在主に使われているレンダリング手法はラスタライズと言われる手法です。
ラスタライズ
ラスタライズでは、画面上の物体はその 3D モデルを構成する仮想的な三角形や多角形 (ポリゴン) の組み合わせ (メッシュ) で生成されます。メッシュでは、各三角形の頂点がサイズや形状の異なる他の三角形の頂点と交わり、各頂点には空間内の位置、色、テクスチャや法線に関する情報など多数の情報が関連付けられます。3D モデルの各三角形は 2D 画面上のピクセル に変換されるが、このとき三角形の頂点に格納されたデータから色の初期値が割り当てられ、さらにシーン内の光がピクセルにどのように当たるかによって、ピクセルの色の変更やピクセルに対する複数枚のテクスチャの適用などによるシェーディングの組み合わせによって、ピクセルに適用する最終的な色が生成されます。例えばシャドウマップにより影を落としたり、SSR (ScreenSpaceReflection) 等を用いて反射を再現します。
すなわちラスタライズは、プリミティブ単位でレンダリングする手法です。
レイトレーシング
それに対してレイトレーシングは、光の反射、屈折、陰影を正しく表現することにより、フォトリアリスティックな表現を実現するもので、光源から視点に至る光の伝搬を物理法則に基づきシミュレーションするものです。
古典的レイトレーシングでは、視点から逆向きに光線を追跡し、拡散反射や鏡面反射を追跡して光源に到達した光線を合計して最終的な色が生成されます。拡散反射については光源からの直接光のみを用いて近似します。
一方モンテカルロレイトレーシング(いわゆるパストレーシング)は、ランダムサンプリングによって近似して計算量を減らす数値計算手法で、メトロポリス光輸送法等により、拡散反射による間接光も考慮してレンダリング方程式を解くものです。特に、光源からフォトンを散布し、視点からの光線追跡の際に出会ったフォトンから放射輝度を算出するフォトンマッピング法は、効率的に拡散反射のレンダリング方程式を解く手法です。
すなわちレイトレーシングは、光を追跡しピクセル単位でレンダリングする手法です。
レンダリング方程式
こちらはグランツーリスモを開発しているチームがCEDEC 2018で行った講演 “ゲーム開発のためのレイトレーシング” の資料からの引用です。グランツーリスモは、事前レイトレーシング+ラスタライズ的なアプローチで、以前からフォトリアリスティック感の高い画作りで有名ですね。興味がありましたら資料全体に目を通してみてください。
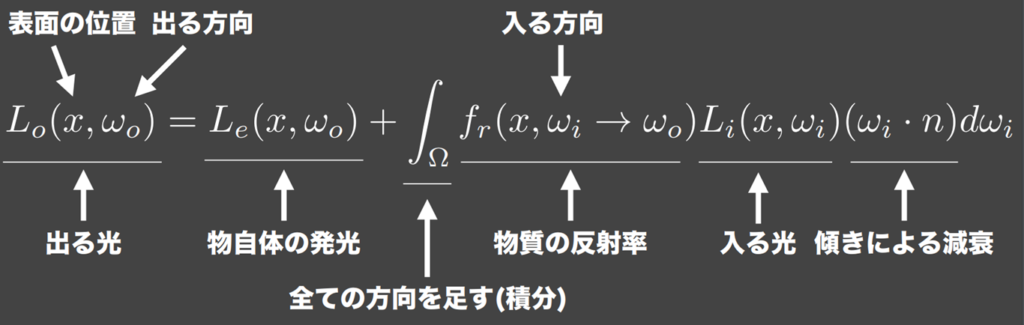
さて、レンダリング方程式とはこういうものです。
ある位置である方向に出る光は、その位置からその方向に自発光で出る光と、それ以外の反射光の総和によって表現されます。 の角度で入る光が
の角度で入る光が の方向に出ていく反射光は、入る光に対してその入射出射における反射率と減衰項の積によって表されるので、これをすべての入射光で積分したものがの方向に出ていく反射光になります。問題はこの積分項なわけですが、真面目に計算すると計算量が膨大になってしまうので、ランダムサンプリングによって有限の計算回数で反射光を近似するのがパストレーシングというわけです。
の方向に出ていく反射光は、入る光に対してその入射出射における反射率と減衰項の積によって表されるので、これをすべての入射光で積分したものがの方向に出ていく反射光になります。問題はこの積分項なわけですが、真面目に計算すると計算量が膨大になってしまうので、ランダムサンプリングによって有限の計算回数で反射光を近似するのがパストレーシングというわけです。
Global Illumination は、このプロセスをかみ砕いてわかりやすく説明していますので、是非目を通してみましょう。
VRとレイトレーシング
VRにレイトレーシングを適用できるか、という話しですが、VRでは双眼の画を描画しなければなりませんし、フレームレートも出さなければなりませんから、リアルタイムレイトレするのはまだ時期尚早の感があります。しかし、Foveated renderingやVariable Rate Shading的な手法で、ユーザーが注視している場所を中心に部分的にレイトレーシングによるフォトリアリスティックな画作りを行うことは、じきに可能になるでしょう。
VR機器のグラフィクス その1とその2でやりましたが、VRではいわゆるRoational Reprojectionという技術により、ゼロレイテンシーを実現しています。回転方向だけなので画を回すだけで対応が可能なわけですが、実際には並進運動も対応すべきです。しかし並進運動を考慮するとオクルージョン(見えてなかったものが見えるようになること)にも対応しなければなりません。まだ学術レベルですが、この比較的微小なオクルージョン補償にレイトレーシングを適用する動きがありますので、いずれ軽く触れたいと思っています。
ということで、パストレーシングによるフォトリアリスティックなVR Minecraftのビデオを見てみましょう。
どうでしたか?Minecraft なのでどんな感じなのかなと思いましたが、水やブロックの表面がかなりフォトリアリスティックで、夕日も美しかったですね。
昨年まではこれでおしまいにしていたのですが、2022年に入りいよいよフルレイトレーシングのXRへの適用が始まりました。こちら (「VRゲームにリアルタイムレイトレーシング技術が導入される? NVIDIAがシステムを開発中」) にもまとまっていますが、NVIDIAの “Omniverse XR” です。フルレイトレーシング + Fixed Foveated Renderingによって現状実現しているようで、推奨環境はRTX 3090 x 2とのこと。
Omniverse XRの適用事例もいろいろ出てきましたね。こちらは網膜解像度のVR HMDで有名なVarjoのバーチャルCar Showroomです。光源自体はあらかじめ設定したものですが、ユーザーの視点に応じてリアルタイムレイトレーシングによるフォトリアリスティックな車が表現されています。では最後にこのビデオを見てみましょう。
おわりに
今回は少し長くなってしまいましたが、VR・ARを間接的にささえる技術、あるいはコンテンツ制作に重要な技術として、360度動画、セグメンテーション、ライトフィールド、レイトレーシングの4つについて勉強しました。
360度動画は、一番シンプルなVR機器でもよいので、スティッチング探しをしてみてください。またセグメンテーションに限らず、昨今AIと呼ばれているニューラルネットワーク系の技術はソースコードが公開されていることが多いので、是非試してみてください。ライトフィールドはなかなか奥が深い技術ですが、VRにしろARにしろ3D立体視は輻輳的には正しくても、レンズ(水晶体)厚みとしては間違っていることが多々あることを覚えていてください。輻輳とレンズ厚みの関係の不一致 (Vergence-accommodation conflict) は眼精疲労を招く可能性があります。そして最後はレイトレーシングでした。VRコンテンツにリッチなレイトレが適用されるのはまだ少し先と思われますが、ホラー系のコンテンツがフォトリアリスティックになったら相当怖いだろうと想像します。今でも十分怖いんですけどね。
次回はVR・AR技術の適用事例に触れて行きます。次回もお楽しみに !