
3/25~29の日程でIEEE VR 2023がありました。今年は中国の上海開催で、日本との時差は1時間、かなり参加しやすかったですね。そして今回はバーチャルとリアルのハイブリッド開催ということで、久々にリアルでの参加も可能となりました。中国開催ということもあり、リアル側もかなりの盛況を見せていましたね。世界中から中国人が帰ってきた感が伺えました。もちろん欧米からの参加者も見えましたが、圧倒的に中国系の方が多かった印象です。
そして過去3年はリモート開催ということで、参加費用が大変リーズナブルでしたが、今回からは元に戻った感じで、リモート参加の聴講者はまだお得な価格設定になっていましたが、リモートからの発表者の費用は結構お高く、リアル側に寄せたい開催者側の思いを感じました。

全スケジュールはこちらがわかりやすいです。3/25, 26はWorkshopで、3/27~29の三日間は数々のPaperセッションを中心にPosterセッションやKeynote/Panelセッションが開催されました。ここでは3/27 (Day1) のPaperセッションの内容を全網羅してみました。Abstractの翻訳レベルではありますが、トピックが多岐に渡ることが見て取れると思いますので、是非目を通してみて下さい !
Session 1: Tracking
Simultaneous Scene-independent Camera Localization and Category-level Object Pose Estimation via Multi-level Feature Fusion

SLO-LocNetがカラー画像とデプス画像からlocalization featuresを生成。SLO-ObjNetがデプス画像のpoint cloudからpose estimationを行う。これを2フレームで行いfeature sharingを行うことにより、category-level pose estimationとscene-independent localizationを同時に達成する。
SCP-SLAM: Accelerating DynaSLAM with Static Confidence Propagation
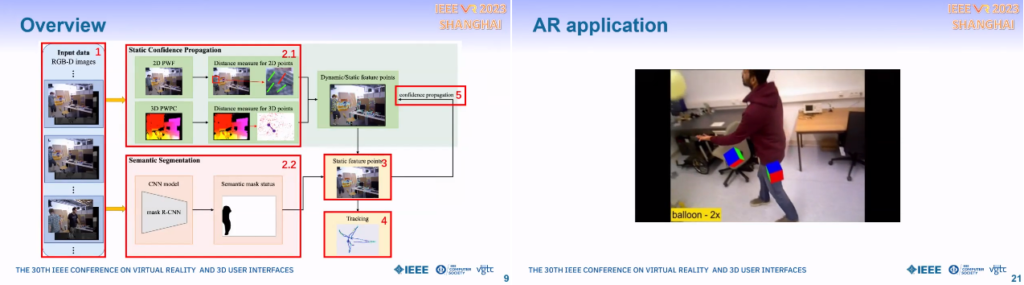
Dynamic SLAM methodとしてlearning-base(精度は良いが計算負荷が高い)とgeometry-base(比較的軽いが位置精度があまりよくない)を融合したSCP-SLAMを提案。RGB-D画像を入力とし、Static confidence propagationがdynamic/static feature pointsを出力、並行してSemantic segmentationがstatic feature pointsを出力、融合した結果 (static feature points) からtrackingを行う。
AR-MoCap: Using Augmented Reality to Support Motion Capture Acting
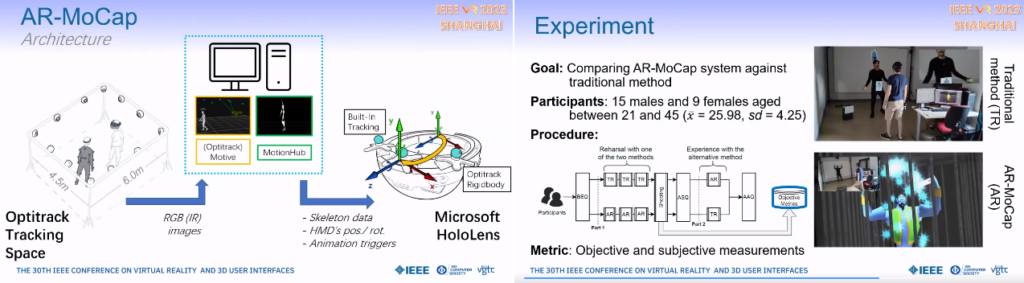
OptiTrackによって自分と第三者のトラッキングを行い、HoloLensでARオブジェクトに変換して表示するもの。第三者がキャラクター化するだけでなく自分の手などもAR化する。
Cross-View Visual Geo-Localization for Outdoor Augmented Reality

Outdoor ARにおいて、絶対的な位置や方位を知ることは重要である。シーン画像を衛星画像にマップしその位置や方位に応じてARオブジェクトをシーン画像に重畳する。トランスフォーマーベースのNeural networkによりSOTA preformanceを達成した。
LiDAR-aid Inertial Poser: Large-scale Human Motion Capture by Sparse Inertial and LiDAR Sensors

LiDARセンサーに加えて4つのIMUセンサーを利用することにより精度の良いpose estimationを実現した。Poseだけでなく人の位置や方向も精度よく推定している。
Session 2: Collaboration
Comparing Visual Attention with Leading and Following Virtual Agents in a Collaborative Perception-Action Task in VR
ユーザーの視覚注意の挙動に関するもの。Virtual Agentとの共同作業において、VAがリーダー役を行う場合とフォロワー役を行う場合でユーザーの視覚注意の挙動に顕著な違いがあることがわかった。
Towards an Understanding of Asymmetric Collaborative Visualization on Problem-solving
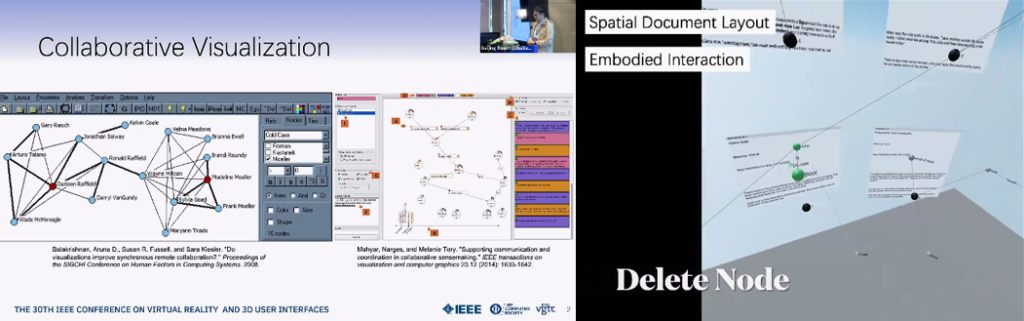
ドキュメントが3D空間にばらまかれておりNodeをdelete/mergeしたりLinkをcreate/deleteする共同作業において、PC-PC, PC-VR, VR-VRでのPerformance等を比較した。Interaction designをPC, VR双方で使い勝手がよくなるよう最適化したところ、PC-VRという非対称な環境でもPerformanceは変わらないことがわかった。またVisualizationとCommunicationが重要であることがわかった。
MAGIC: Manipulating Avatars and Gestures to Improve Remote Collaboration

バーチャルな3D空間における共同作業はあいまいさ、オクルージョン、異なる視点などが原因でわかりにくい場合がある。対面で作業するよりも、横並びでほぼ同じ視線で作業をする方がわかりやすいということと、MRの特性を利用して、Magicは対面でありながらpointしたときにVirtual objectを相手側に向けて表示し,さらにpointingの動作も見えやすいように表示するものである。
Effects of Collaborative Training Using Virtual Co-embodiment on Motor Skill Learning

VR空間で身体を動かして行う作業をTeacherから教わる場合において、Third person視点のAvatorを共有する(50%ずつ動きをmixする)Co-embodimentと、First person視点で双方の手の画像を共有するPerspective sharingと、Aloneを比較したところ、Co-embodimentがパフォーマンスが最も良いという結果になった。
Using Virtual Replicas to Improve Mixed Reality Remote Collaboration

Remote collaborationのパフォーマンス改善に関する。MR環境での3Dパズルにおいて、物理的な3D pieceの形状を3D annotation drawingした場合と、Virtual replicaを表示した場合で、後者に顕著な改善が見られた。
Session 3: Agents
Exploring the Social Influence of Virtual Humans Unintentionally Conveying Conflicting Emotions

表情と声でミスマッチな感情表現があった場合の感情理解に関する。Unhappy/Neutral/Happy x Facial/Vocalに加えて、大中小3段階のHead scaleを用意し、顔の大きさが与える影響についても評価した。結果、Facial/Vocalでの感情表現の組み合わせとTrust perceptionには顕著な関係が見られたが、Head scaleとは顕著な効果は見られなかった。これはAvatar作成の際のガイドラインとして有用な情報である。
Studying Avatar Transitions in Augmented Reality: Effect of Visual Transformation and Physical Action

Avatarの形状変化のタイミング形成の違いが与えるSense of Embodimentへの影響に関する。ユーザーのPhysical actionでAvatarがMuscular-shapeになる場合と自動的に変化する場合で、前者の方がSoEを維持しつつProteus効果を強める効果が高いことがわかった。
Animation Fidelity in Self-Avatars: Impact on User Performance and Sense of Agency

異なるタスクにおいて、Avatar animationの実人間の動きへの忠実度が与える影響に関する。6トラッカーを用いたInverse Kinematicsベースの手法と、17センサーのMoCapで比較した。結果身体の動きの正確な反映は自己身体感覚を高めることがわかった。また驚くことに、スピードが求められるタスクの場合は、Latencyが大きいMoCapよりも軽いIKベースのもののほうが優れていることもわかった。
Fully Automatic Blendshapes Generation for Stylized Characters

Source avatarからTarget avatarのBlendshapeを生成するDeformation transferに関する。Variational AutoencoderによりLatent spaceを取得し、Multilayer PerceptronによりSourceのLatent spaceからTargetのLatent spaceへの変換を実現した。
PACE: Data-Driven Virtual Agent Interaction in Dense and Cluttered Environments

Motion-capturで抽出した実人間の動きをVirtual worldの環境に合わせて変化させ、Virtual agentsの動きに適用するもの。密で散らかっている環境では特に適切な変化が有効だが、PACEはそのような環境下でも自然なObject interactionを実現するもの。
Session 4: Locomotion 1
Designing Viewpoint Transition Techniques in Multiscale Virtual Environments
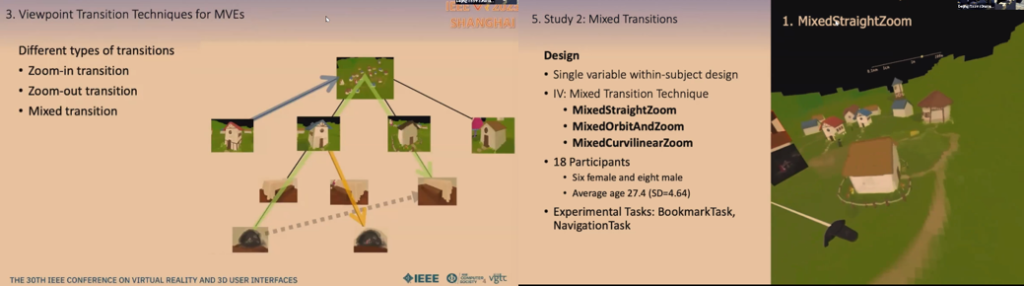
奥行き方向にスケールを変えられるMVEにおいて、Zoom-in/Zoom-out/Mixed transitionにおける視点の変化はユーザーの空間認識において重要である。Nest構造のMVEのNavigationにおいて、異なる変化手法が空間認識やUsabilityに与える影響を評価した。
Assisted walking-in-place: Introducing assisted motion to walking-by-cycling in embodied Virtual Reality

足で漕ぐ手法を使ったWIPに関する。アシスト付きのwalking-by-cyclingにより、通常のWBCより少ない負荷で同等の歩行間隔を得ることが可能となった。
Monte-Carlo Redirected Walking: Gain Selection Through Simulated Walks
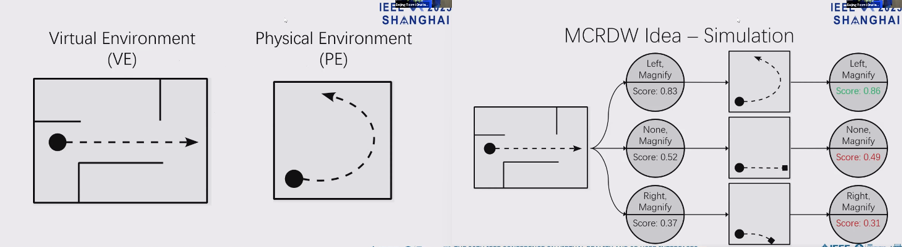
MCRDWはVirtual空間の状況に応じてRDWのゲインと方向を変えるものである。既存手法と比較して、境界衝突の頻度を半分以下に減らしかつ実空間における総回転角度や移動距離の削減を達成した。
A Systematic Literature Review of Virtual Reality Locomotion Taxonomies
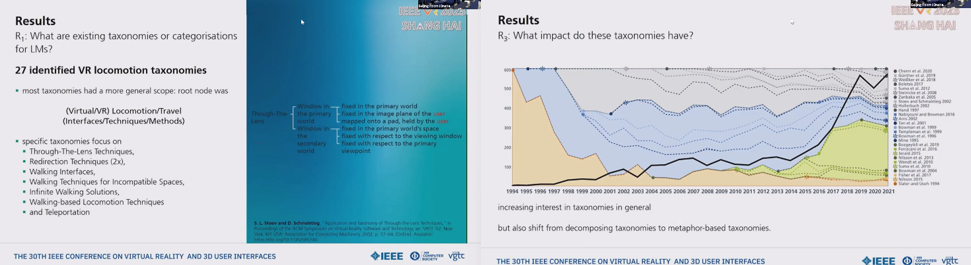
VR Locomotionに関する文献は増え続けており、Locomotion手法の分類に関する。システマティックな分類(WordNetを利用した意味論的同義性の評価)により、587文献から代表的な27論文に絞り込んだ。代表的なものとして、レンズ越しの技術、Redirection、Walking interfaces, 非互換空間での歩行手法、無限歩行、歩行ベースのLocomotion手法、Teleportationなどである。
Revisiting Walking-in-Place by Introducing Step-Height Control, Elastic Input, and Pseudo-Haptic Feedback
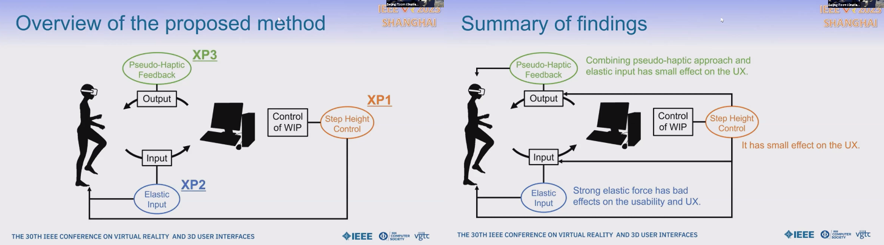
WIPに対し3つの新しい手法を適用した。一つ目は足を大きく上げるとVirtualな移動距離が大きくなる手法。二つ目は足裏に弾性/傾斜情報を持たせる入力手法。三つめは疑似Haptic feedbackを与える手法。一つ目はVirtualな高速移動を簡単で効果的に行え、二つ目は上り感覚が安定したVirtual speed controlを実現したが、過度の傾斜はUXに悪影響を及ぼした。三つ目はVirtual slopeの現実感向上に寄与した。
Session 5: Audio
Lightweight Scene-aware Rain Sound Simulation for Interactive Virtual Environments

シーンに合った雨音を軽いリソースで生成する技術に関する。まず、Exponential移動平均をベースにした周波数領域での加算合成手法により、基本の雨音を拡張変更を可能にした。次に、Near field伝達関数をベースにした効果的なBinaural renderingによりシーンにマッチした3D音響を生成した。提案手法はシーンに合ったリアルな雨音の生成について劇的に改善した。
ConeSpeech: Exploring Directional Speech Interaction for Multi-Person Remote Communication in Virtual Reality

ConeSpeechは複数ユーザー間のコミュニケーション技術で、相手を選んで話すことができ、他社に悪影響を与えないものである。本技術ではユーザーがTarget listenerを見つめることにより、Cone形状のエリアのみ話しが聞こえる。このCone形状のエリアの形成手法として二つの手法を提案し、三つの多人数でのコミュニケーションタスクで比較した。
The Design Space of the Auditory Representation of Objects and their Behaviours in Virtual Reality for Blind People
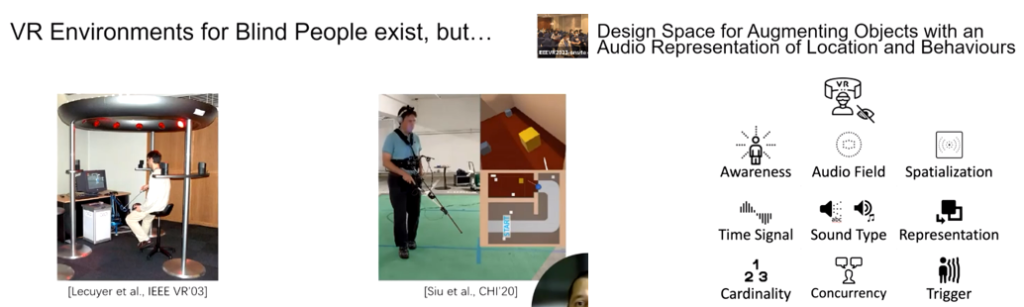
VRは視覚体験が基本であるが、盲目者向けにVR環境が理解できInteractできる環境を提案する。すなわち、物体やそのふるまいを音で表現する。Boxing (defend and attack) の二つのシナリオで評価を行った。しかしながら万能解のようなものはなく、個々の体験を紐解いていく必要がある。
Emotional Voice Puppetry

オーディオベースのFacial animation技術に関する。口の動きと口周辺の表現はコンテンツの音声データから生成され、顔全体の動きは感情種別とその強さから表現される。正確な位置情報からの表現ではなく、それらしく認識されることが目的である。また、様々なキャラクターに適用可能であることが特徴である。
Persuasive vibrations : Effects of Speech-Based Vibrations on Persuasion, Leadership, and Co-Presence During Verbal Communication in VR

スピーチと同期してVibro tactile feedbackを与えることの効果に関する。二人のVirtual Agentの話しを聞く場合、片方のVAが話す場合のみTactile feedbackを与えた場合、共存感や説得力の向上が認められた。またVAに話す場合にTactile feedbackを与えた場合も共存や説得力の向上が認められた。
Session 6: Rendering 1
ShadowMover: Automatically Projecting Real Shadows onto Virtual Object

屋外のシーンでVirtual objectに自動的に影をつけるEnd-to-end solutionに関する。Shifted Shadow Mapは実際の影を変形して影を生成するもので、CNNベースの影生成器 (ShadowMover) がまず入力画像のShifted Shadow Mapを推定し、Virtual objectに対して自動的にもっともらしい影を生成する。
Add-on Occlusion: Turning Off-the-Shelf Optical See-through Head-mounted Displays Occlusion-capable

Add-on Occlusion: Turning Off-the-Shelf Optical See-through Head-mounted Displays Occlusion-capable
Occlusion表現を許容したOptical see-throughのHMDが活発に開発されている。しかし実装が複雑などの問題があった。ここでは新しいアプローチとして、OSTHMDに追加デバイスをAdd-onする形でOcclusion表現を可能にするシステムを提案している。Hololensを使用して想定通りの性能が実証された。
NeRFPlayer: A Streamable Dynamic Scene Representation with Decomposed Neural Radiance Fields

本技術は高速な再構成、コンパクトなモデリング、そしてストリーム可能なレンダリングを4Dの時空間で実現するもの。Frameworkは4D空間をstatic, deforming, new areasの3種類のカテゴリーに分解し、それぞれが別々のネットワークで再構成される。Single cameraとCamera arrayで評価を行い、品質とスピードの両面で同等か優れた性能を達成した。1フレーム10秒で再構成された。
Integrating Both Parallax and Latency Compensation into Video See-Through Head-Mounted Display

Video see-through HMDにおいて、視差と遅延の両方を補償し、エッジをきれいに見せるOcclusion表現を実現する技術に関する。Captureしたimageから再構成するために、Depth mapを利用して目に入る画像を再投影する。また遅延補償としてTwo-phase temporal warpingという手法を提案している。これにより、高速で空間的にも正しいシーンの生成が可能となった。
GeoSynth: A Photorealistic Synthetic Indoor Dataset for Scene Understanding
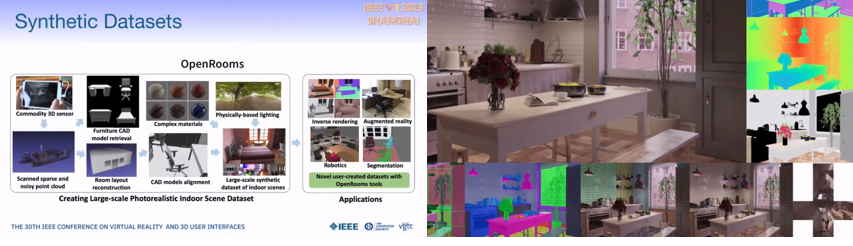
DLはシーン認知において革新的な発展を遂げてきた。そこでは巨大なデータセットのラベル付けに帰するものも少なくないが、非常に手間と時間がかかったり不完全だったりする。この問題を鑑みて、Indoor scene understanding向けの多様なフォトリアリスティック人工データセットであるGeoSynthを紹介する。GeoSynthはsegmentation, geometry, camera parameters, suface material, lightingなど豊富なラベルを持ち、ネットワーク性能の改善に大変有用である。
Session 7: Cybersickness and Social Emotional
Cybersickness, Cognition, & Motor Skills: The Effects of Music, Gender, and Gaming Experience
VRでの認知、運動、読み取り性能における酔いの影響を評価し、音楽、性別、コンピュータ/VR/ゲームの経験度の酔い軽減への影響を評価した。楽しいあるいは落ち着いた音楽はNausea(吐き気)の兆候を軽減した。楽しい音楽だけが顕著に酔い全体を軽減した。酔いはしゃべるタスクにおける記憶性能を劣化させ、瞳孔サイズも小さくなった。また、反応時間や読み取りスピードにも劣化が見られた。ゲーム経験は酔いとは相反する相関があった。また、同等のゲーム経験がある場合酔いやすさに男女の差異は認められなかった。
Effect of Frame Rate on User Experience, Performance, and Simulator Sickness in Virtual Reality
ユーザー経験、性能、酔いに対してフレームレートが与える影響を評価した。2種類のVRアプリケーションを60/90/120/180fpsで行った場合を評価した。結果120fpsが重要な境界条件となることがわかった。120fps以上だと、ユーザー経験や性能を劣化させずに酔いの兆候を低減できていた。よって120/180fpsが良いユーザー体験を実現することがわかった。
Intentional Head-Motion Assisted Locomotion for Reducing Cybersickness

自己受容感覚と調和した頭の動きを利用したロコモーション(並進と向きの変更)手法に関する。ロコモーションイベントはコントローラーによってトリガーされ、同時に頭の動きでコントロールされる。さまざまな速度での実験から、最も遅い速度のときに最も高い酔い度が印加された。また速度と酔い度の関係はU型の関係になった。これは新たな知見である。また、コントローラ/Teleportationとの比較から、コントローラよりも酔い度は低く、Teleportationよりも臨場感が向上した。
Mitigation of VR Sickness during Locomotion with a Motion-Based Dynamic Vision Modulator

コントローラーによる連続ロコモーションにおいて酔いは深刻な問題である。本研究は、動き/色/デプス情報をベースに周辺画像のコントラストを変更することによって動的にユーザーのFOVを変調し、酔い軽減を実現するものである。この変調器は酔いの原因とされる加速、機銃掃射、線形速度といった特定の動き印加時に動作するShaderで、アルゴリズムは速度差分、角度差分、色平均によって動作するものである。2種類の変調時間で二つの実験を行った結果、高速な変調が効果的なことがわかった。
The Effects of Spatial Complexity on Narrative Experience in Space-Adaptive AR Storytelling
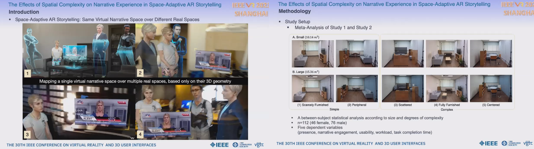
ARで空間に適応した物語りをすることは、実空間の種類によらず首尾一貫した臨場感のユーザー体験を提供するという挑戦である。本研究では、屋内スペースのサイズ、密度、レイアウトがユーザー体験に与える影響を評価するため、空間適応型AR探偵ゲームを用いて評価した。中庸なレベルの可動性と視覚的複雑性の環境が物語り経験には適切であると仮定した。結果、狭くて比較的シンプルな部屋が最もスコアが高かった。広い部屋よりも影響度が低かった。
Session 8: 360Video, 3D Video and applications
Introducing 3D Thumbnails to Access 360-Degree Videos in Virtual Reality
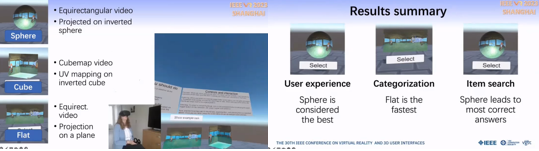
VRで360度ビデオのデータセットにアクセスする場合、データが3Dであっても2Dサムネイルを使用することがほとんどである。そこで、球型やキューブ型の3Dサムネイルを利用することにより、より良いユーザー体験を提供でき、コンテンツのハイレベルな主題を伝達したり、特定の何かを探す場合により効果的であることを確認した。結果ハイレベルな選別タスクでは従来の2D長方形投影の方が優れていたが、ビデオの中から詳細な何かを探すタスクでは球型サムネイルが優れていた。
Masked360: Enabling Robust 360-degree Video Streaming with Ultra Low Bandwidth Consumption

Masked360はニューラルネットワークにより性能を高めた360度ビデオストリーミングフレームワークで、バンド幅を大幅に低減し、パケットロスに対するロバスト性を達成した。Masked360では完全なビデオフレームを送るのに対し、サーバーではバンド幅を大幅に低減するためにマスクされた低解像度のフレームのみを送信する。一方クライアントは軽いニューラルネットワークにより元の360度ビデオフレームを再構成する。さらにビデオストリーミング品質の向上のため、複雑性ベースのパッチ選択、1/4マスク戦略、冗長なパッチ送信、トレーニング性能の強化などの最適化手法も提案している。
Wavelet-Based Fast Decoding of 360 Videos
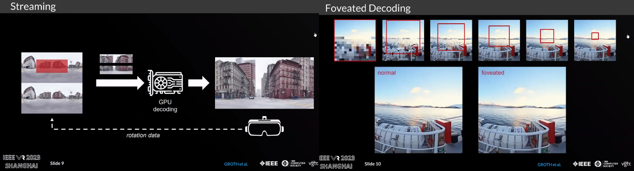
本研究では高解像度360度ビデオのリアルタイム再生を可能にするWaveletベースのビデオコーデックを提案する。本コーデックはドライブからダイレクトに適切なコンテンツをストリームし、視点依存のビデオをデコードする。特別なデザインとフレーム内およびフレーム間のWavelet変換の利用により、本コーデックのデコード性能はSOTAに比べて272%高速である。また、中心窩の考慮によるさらなる性能向上についても示した。
CaV3: Cache-assisted Viewport Adaptive Volumetric Video Streaming
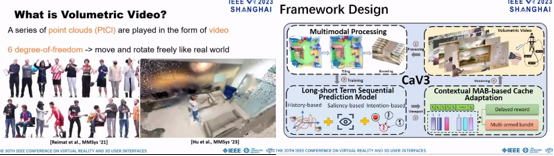
Volumetric videoは最近出現した新しいビデオアプリケーションで、フォトリアリスティックで臨場感高い3D鑑賞体験を提供する。現状は視界の推定から適応型VVストリーミングに焦点をあてたものが主流であるが、その効果は非常に限定的である。むしろ、視界におけるコンテンツの繰り返し性をもっと利用すべきである。本研究ではクライアント側にキャッシュを持たせ、繰り返し現れるVVタイルをバッファーし、冗長なデータ転送を削減するものである。CaV3はSOTAと比較して視界推定においてもシステムの実効性能においても顕著な向上を達成した。
Scaling VR Video Conferencing
VRプラットフォームは、何千人というユーザーをライブやスポーツイベント、会議など継ぎ目のない仮想空間で扱う必要がある。現状は、ユーザーをいくつかのグループに分け並列のセッションに分離するような方向性が主流である。本研究では何百というユーザーを一つの仮想環境で扱うためのアーキテクチャを提案する。ここでは二つの最適化によってユーザーの位置関係から優先度付けする : 1)ユーザーの位置関係に応じて情報量の優先度付けを行う、2)ユーザーの近さに応じて複数サーバーに対してクライアント接続をアロケートする。実験から提案システムのスケール性を示した。
Session 9: Locomotion 2
Tell Me Where To Go: Voice Controlled Hands-Free Locomotion for Virtual Reality Systems
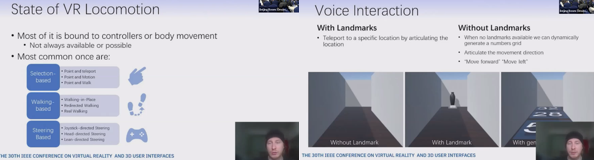
ロコモーションはVRの臨場感や使いやすさを向上する上で重要なファクターであり、VRアプリケーションの成功にとって重要な側面を持ち続けている。昨今様々な手法が提案されているが、それはテレポーテーションのようなアバウトなものから動きやジェスチャーなどより現実的なものまで幅広い。しかしながら、アプリケーション全体へのアクセス性や無菌室での医療シナリオのようなハンズフリーのシナリオに対しては、多くの技術は適用不適切である。そこで本研究ではスピーチを利用した直感的なナビゲーション手法を提案する。
Investigating Guardian Awareness Techniques to Promote Safety in Virtual Reality
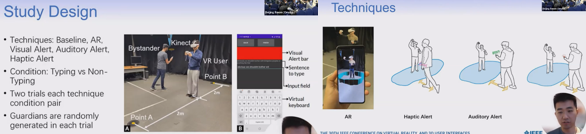
VRでは仮想空間に没入するため実環境についてはほとんど気付かない。現状のVRでは安全境界として予め定義されたガーディアンが用いられている。しかしながら、傍観者は境界を認識できないので、彼がガーディアンの中に入ってしまうとVRユーザーと衝突する可能性が生じる。この対策として4つの技術を比較評価した。これらの技術は、ARオーバーレイや視覚/聴覚/触覚的なアラートで傍観者にガーディアンに近づいていることを知らせるものである。どの技術も傍観者が境界に近づくのを効果的に避けることができたが、ARオーバーレイが一番即座な対応ができ、触覚アラートが最も没入感を損なわなかった。
Redirected Walking Based on Historical User Walking Data

本研究ではユーザーの歩行データ履歴を解析し利用することによってリアルタイムにRDWの制限を効果的に排除する新しい手法を提案する。ユーザーの歩行履歴から得られる重み付き方向グラフを使い、異なる到達点のスコアを更新し、ユーザーに最適なターゲットを知らせる。シミュレーション実験ではかなり効果的だったため、さらにユーザーの歩行軌跡をシミュレートする手法を確立し、データセットを生成した。実験より本手法はさまざまな仮想環境レイアウトにおいていくつものSOTA手法よりも優れていることを示した。
Gaining the High Ground: Teleportation to Mid-Air Targets in Immersive Virtual Environments
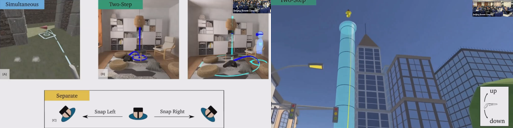
本研究ではユーザーに地面だけでなく空中を移動できる3種類のテレポーテーション手法を提案する。手法は従来のターゲット選択に対して高さ変化の度合いが異なる。高さは、同時、連結する2ステップ目として、あるいは水平方向の動きとは分離してコントローラから指定できる。ユーザー実験の結果、同時の場合が最も正確であり、2ステップ目の場合がもっと負荷が低かった。分離型がもっとも不適切であった。この結果をベースに、空中ナビゲーション手法について最初のガイドラインを作った。
FREE-RDW: A Multiuser Redirected Walking Method for Supporting Nonforward Steps
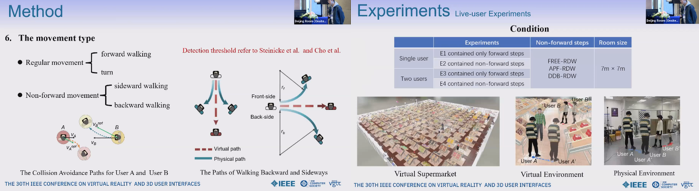
前進以外のRDWはユーザーのバーチャルなぶらつき歩行の動きを豊富にできる。加えて、前進以外の動きは大きな曲率を与えることができ、RDWのリセットを減らす効果が期待できる。本研究は複数ユーザーのRDWに関し、横方向と後方へのステップを加え、VRロコモーションを拡張するものである。本手法は最適相互衝突回避 (ORCA) をベースにユーザー同士の衝突を避けるものであり、最適速度の取得のために線形プログラミング問題を最適化した。実験から仮想シーンでのロコモーション性能は良好であった。
Session 10: Rendering 2
Level-of-Detail AR: Dynamically Adjusting Augmented Reality Level of Detail Based on Visual Angle

本研究は、文字やインタラクションできるコンテンツをアプリケーションに対する視覚角度に基づいて見やすさ、インタラクションのしやすさを考慮し動的にレンダリングするLevel-of-Detail ARメカニズムに関する。また、タスクパフォーマンス、ユーザーの距離、主観的満足度を評価した。結果、タスクの種類によってユーザーパフォーマンスに大きな差異が認められた。満足度は一貫して本手法が高かった。
Where to Render: Studying Renderability for IBR of Large-Scale Scenes
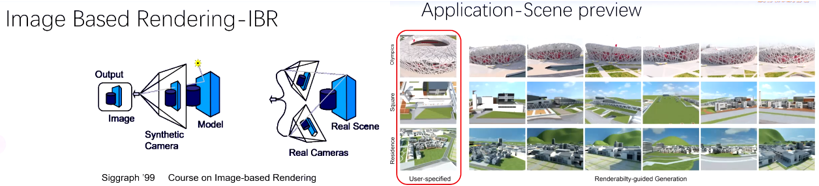
本研究は視点位置や距離に応じたIBRの品質を推定するようなレンダリング性に関する。5Dカメラパラメータ空間で評価されたレンダリング性値は、IBRに対する視点/軌跡選択が効果的に行えたかを示すものであり、特に大規模な3Dシーンにおいては挑戦的なものである。
Delta Path Tracing for Real-Time Global Illumination in Mixed Reality

MRにおいて実物とバーチャルオブジェクトの間の視覚的一貫性は重要である。しかしながら、挿入されたバーチャルオブジェクト由来の照度変化をリアルタイムに計算するのは困難である。本研究ではDelta path tracing (DPT) を提案する。DPTは光源からの光でバーチャルオブジェクトにブロックされたもののみをPath tracingの最初のヒット点で計算する。DPTは直接光の参照回数を減らし、性能向上のためにシーンを2回レンダリングすることを避ける。DPTはGPUのハードウェア支援によるRay tracing機能を利用して実装され、リアルタイムに実物と視覚的に一貫したバーチャルオブジェクトを自然に生成することができた。
Style-aware Augmented Virtuality Embeddings (SAVE)

本研究ではVRシーンにマッチしたスタイル表現を実物に施すAugmented virtuality pipelineに関する。ユーザーに臨場感高いインタラクションを可能にする。Pipelineは3つのステージから構成される:一つ目は対象物をVRヘッドセットでの撮影画像とそれに対応する撮影時のカメラ角度から再構成し、あるいは別途ShapeNetデータセットからFitting meshを取得する。二つ目はスタイル変換手法を適用し、一貫した臨場感を与えるためにVRゲームシーンにオブジェクトのメッシュを施す。三つめはスタイル表現されたメッシュをリアルタイムに実物に重畳し、対象物が動いた際にもインタラクションできるようにする。このPipelineはスタイル表現AVのPoCとして使用可能である。
LFACon: Introducing Anglewise Attentions to Light Field Space in No-reference Quality Assessment
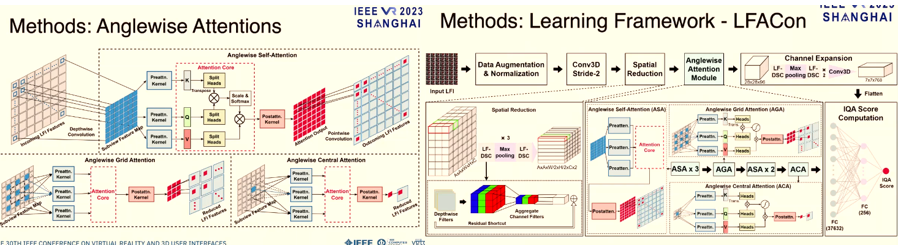
2Dイメージの評価と比較して、Light field image quality assessment (LFIQA)は空間方向の画像品質だけでなく角度方向の品質一貫性を考慮する必要がある。本研究ではLFIの角度方向に対してmultihead self-attention構造を適用した’anglewise attention’という新しい概念を提案する。この構造はLFI品質をよく反映している。さらに、本手法をベースにしたLight field attentional convolutional neural network (LFACon)をLFIQAメトリックとして提案する。結果として、SOTAと比較して顕著に優れたメトリック性能が確認された。
さいごに
以上IEEE VR 2023のPapaerセッションDay1をまとめました。Day1だけでもかなりのボリュームですね。これに加えて同量程度のPosterセッションもありましたので、全部を把握するのは結構大変でした。が、参加費用もバカになりませんので、出来る限り全部吸収しておきたいものです。
個人的にはDay1だとRenderingが面白かったですが、TrackingやCybersicknessも興味深い内容がありました。あと全トピックにわたってDeep Learning関連が幅を利かせていますが、その傾向は強まる一方という印象です。
次回はDay2をお届けします。お楽しみに !